Remarks¶
In this section I want to mainly give some fairly informal remarks. Many are on different Abel transform algorithms described in literature, and for those I’m giving the reasoning on why these algorithms were not useful to me. The remaining remarks are just a collection of findings of me related to the Abel transform I thought worth mentioning. Some of the remarks are fairly subjective for the use cases I was and am interested in. Furthermore, while this section is meant to be fairly informal, I try to be direct, especially since I feel like many publications are somewhat misleading, e.g. algorithms are often mislabeled as “fast” or “similar to the Fast Fourier Transform” even though the computational complexity is nowhere near similar to the Fast Fourier Transform.
PyAbel Python Package¶
There is a Python package called PyAbel, which focuses mainly on the inverse (or backward/reconstruction/etc.) Abel transform. It’s open source and pretty well documented and has a several nice and communicative developers which are active on the PyAbel github repository.
If the reader is interested in testing many of the algorithms mentioned in this remarks section, I can only recommend to look at PyAbel, as it does implement more algorithms for the inverse Abel transform than openAbel (basically all except the main recommended one in openAbel) . The example_005 of openAbel uses PyAbel to compare many of the algorithms talked about here as well.
Hansen-Law Method¶
Although the Hansen-Law method is still implemented in openAbel, it unfortunately has one major flaw (and one slightly problematic one). I think in principle the space state model approximation is a pretty clever idea. That’s why I actually tried to improve the algorithm or apply the basic idea to other integrals (both to no success, yet). Unfortunately several things have to fall into place for it to work nicely, which isn’t the case for the Abel Transform.
The first approximation which Hansen and Law make is – roughly speaking – that they implicitly approximate the data by a piecewise polynomial, specifically piecewise linear in the original formulation. Going to higher order gets messy quickly, but is in principle possible. I successfully tried that, but due to the next approximation (which is somewhat flawed) it’s not useful.
The second approximation is to rewrite the Abel transform kernel and approximate it by a sum of exponentials. At first it looks like one could get a linear computational complexity 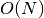 algorithm. Problem is that the kernel has (even after rewriting) a singularity, so it’s obviously pretty difficult to approximate a singularity by a sum of exponentials (again I tried many published approaches for that; most have flaws as well or are at least difficult and don’t lead to good enough results). Increasing the number of exponentials used increases the computational complexity. My guess is that the algorithm is
algorithm. Problem is that the kernel has (even after rewriting) a singularity, so it’s obviously pretty difficult to approximate a singularity by a sum of exponentials (again I tried many published approaches for that; most have flaws as well or are at least difficult and don’t lead to good enough results). Increasing the number of exponentials used increases the computational complexity. My guess is that the algorithm is 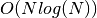 at best because of the increasing number of required exponentials. In practice it turns out it’s pretty much impossible to get anything really universally useful, unless one aims only for fairly large errors (like Hansen-Law with roughly
at best because of the increasing number of required exponentials. In practice it turns out it’s pretty much impossible to get anything really universally useful, unless one aims only for fairly large errors (like Hansen-Law with roughly 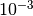 ). For many use cases this is probably enough (e.g. experimental ones which are usually fairly noisy anyway), so the method has still some value. But even if that is the case and one ignores every problem I mentioned here the method is still not more efficient than the main openAbel methods, so it’s never the best choice as long as one does not have to implement the algorithms (FMM is a lot more work to implement than Hansen-Law). And I have to mention that I did a lot of thinking on the topic, and for example one could subtract the singularity in the impulse response, but this usually leads to not useful algorithms or the use of basically the same approaches and algorithms as openAbel to make it competitive, just one is taking a huge detour.
). For many use cases this is probably enough (e.g. experimental ones which are usually fairly noisy anyway), so the method has still some value. But even if that is the case and one ignores every problem I mentioned here the method is still not more efficient than the main openAbel methods, so it’s never the best choice as long as one does not have to implement the algorithms (FMM is a lot more work to implement than Hansen-Law). And I have to mention that I did a lot of thinking on the topic, and for example one could subtract the singularity in the impulse response, but this usually leads to not useful algorithms or the use of basically the same approaches and algorithms as openAbel to make it competitive, just one is taking a huge detour.
Desingularized Quadrature¶
Like the Hansen-Law method the desingularized quadrature is implemented in openAbel, but still mostly a remnant of testing different Abel transform methods and I don’t recommend using it. The basic idea of desingularizing integrals should be familiar to almost anyone who tried to numerically integrate a function with a singularity and wanted to improve convergence. In context of a problem similar to the Abel transform it is discussed by Tausch, which is one of the main references for the Fast Multipole Method in openAbel as well.
I actually tried several higher order versions of this, and the effort is not really worth it, since the end corrections used in openAbel are much more efficient. And it gets very complicated – maybe impossible – to program if one tries to avoid instabilities; I’m actually not sure if my test implementations were definitely reliable. And of course this method, it’s 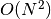 , is slower than the main openAbel methods.
, is slower than the main openAbel methods.
Piecewise Polynomial Analytic Integration¶
There are many different publications which basically use the same idea: Interpolate the data by a piecewise polynomial and use the known analytic integral for every polynomial piece. Dasch calls it onion peeling or filtered back projection, Bordas does basically the same, and there are probably more publications. I actually thought initially when I decided to use the Fast Multipole Method, that the piecewise polynomial analytic integration would be useful in combination. In principle it works, but is again pretty messy and the end corrections used in openAbel are overall much more efficient in every sense once implemented. But without the Fast Multipole Method it’s a slow method as well, and that slow way is what all publications do to my knowledge.
Analytic Integration of a Basis Set Expansion¶
There are many publications which use some kind of basis set expansion applied to the data, then use analytic transform of each basis function to construct the total transform. So this is similar to Piecewise Polynomial Analytic Integration, but with a basis for the whole domain and not just piecewise.
Often a polynomial basis set expansion for the whole data set and then transform each basis polynomial analytically. This obviously only works well (regarding error) if the data has somewhat polynomial behavior regarding the whole domain. Since one can chose orthogonal polynomial basis sets the expansion is at least fairly fast, but since the analytical transforms of polynomials are not very nice this approach overall is not very efficient. In a specific case where the data is basically a low order polynomial this of course would work really well, but in the general case it’s not useful.
Other basis sets might have nicer transforms, but are not orthogonal, so the expansion of the data is more difficult. I tried to find some “good” basis, but in one way or another one shifts the difficulty to another area, e.g. function approximation, and I did not get a useful approach. Again, for some very specific data sets one might find a very small but usable basis set.
One example of such an algorithm in literature is the BASEX algorithm by Dribinski. In this method a “Gaussian” basis set – just to note it’s somewhat Gaussian, not the “normal” Gaussian – is used. It seems to be very popular, as the publication has 791 citations as of writing this. I’m guessing mainly because the code was freely available and the basis set implicitly applied some smoothing in the transform, which usually produces nicer pictures without tweaking than other algorithms. I’m fairly convinced that one can achieve similarly nice results with other methods and some smoothing. Similar to other methods described here the method can be tested in PyAbel. The preprocessing is incredibly painfully slow (it’s 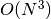 I think, and it takes minutes for even small arrays N=1000, where openAbel’s main methods are and take milliseconds), and the actual transform is not much better ( and openAbel is again). Overall BASEX is a fairly often cited algorithm nevertheless.
I think, and it takes minutes for even small arrays N=1000, where openAbel’s main methods are and take milliseconds), and the actual transform is not much better ( and openAbel is again). Overall BASEX is a fairly often cited algorithm nevertheless.
I can see how in some cases one might be able to chose a nicely suitable basis set to enforce some structure in either the projected or reconstructed data. I expect this would be the only case where such an approach would make sense, but this is very problem specific and thus much less universal than the main methods of openAbel intend to be. One example of such an approach is described by Gerber, and often called linBASEX (e.g. in PyAbel). Due to the underlying physical process Gerber expects or knows that his data has some structure, and enforces it by choosing a specific basis set. In the general case one could probably achieve similar results by fitting the expected structure basis set to the data and then using accurate black-box Abel transform functions like in openAbel.